%20in%20software%20development.%20The%20image%20features%20a%20hierarchical%20structure%20showing%20software%20c.webp)

Darek był doświadczonym programistą backendowym. Pracował nad dużą aplikacją monolityczną obsługującą klientów w branży e-commerce. Kod miał swoje lata, swoje kruczki, ale ogólnie był w porządku — przynajmniej dopóki się nie psuł. A psuł się coraz częściej.
%20looking%20at%20a%20d.webp)
Pewnego dnia Darek postanowił, że nadszedł czas na zmiany. “Ten moduł płatności... aż się prosi, żeby go wydzielić do osobnego mikroserwisu!” — pomyślał.
Refaktoryzacja. Decoupling. Swoboda wdrożeń. Skalowalność. Brzmi pięknie. Co mogłoby pójść nie tak?
Przejście z komunikacji lokalnej do sieciowej
W monolicie wszystko było proste. Jedna metoda wywoływała drugą. Dane wędrowały po stosie w tym samym procesie JVM. Teraz — po wydzieleniu płatności do osobnego serwisu — zaczęło się dziać coś nowego. Darek wystawił endpoint REST i zaczął go wołać z głównego systemu.
Na lokalnym hoście działało to świetnie. Jednak po wdrożeniu na środowisko testowe okazało się, że...
DNS nie rozwiązuje się tak, jak Darek myślał.
Raz działał adres payment-service, raz payment.internal.local, innym razem... nie działał wcale. “Dlaczego curl działa, a HttpClient wyrzuca timeout?” — pytał ze złością. Zrozumiał, że sieć rządzi się swoimi prawami. I że trzeba się zaprzyjaźnić z service discovery.
Opóźnienia i retry
Wcześniej wszystko było instant. Teraz? Zdarzało się, że płatność odpowiadała po sekundzie, a czasem wcale. Timeout. I znowu.
“No to dorzucę retry” — pomyślał. I tak zrobił. Tyle że teraz system zaczął... powielać żądania. Dwukrotne opłaty, chaos w logach, sfrustrowani testerzy.
Nauczył się, że retry musi być idempotentne, a najlepiej opatrzone unikalnym ID żądania.
Circuit Breaker i fallback
Retry to nie wszystko. Mikroserwis płatności zaczął się czasem zawieszać przy dużym obciążeniu. A główny system... zawieszał się razem z nim.
Wtedy Darek odkrył Circuit Breaker. Dodał warstwę zabezpieczającą, która w razie błędu "odcinała" płatności i wrzucała je do kolejki z komunikatem: “usługa chwilowo niedostępna, spróbuj później”. Uratowało to resztę aplikacji.
Samodzielne wdrożenie... i nowe wyzwania
Wydzielenie mikroserwisu oznaczało możliwość niezależnego wdrażania kodu. Super. Do czasu.
Po wdrożeniu nowej wersji płatności logi z głównego systemu zaczęły krzyczeć: “500 Internal Server Error”. Co się okazało?
Nowa wersja zmieniła kontrakt API. Brak zgodności. Brak komunikacji między zespołami. Brak testów integracyjnych.
Darek nauczył się, że niezależność mikroserwisów nie oznacza dowolności. Kontrakty API muszą być święte — albo przynajmniej wersjonowane.
Brak kontraktu... czyli gorzkie lekcje integracji
W pewnym momencie frontend został zmodyfikowany tak, aby korzystał z nowej wersji mikroserwisu płatności. Ale… mikroserwis miał już też innych klientów. Nagle okazało się, że jedna z aplikacji mobilnych nie działa — nowy endpoint miał inny format odpowiedzi.
Darek odkrył wtedy Consumer-Driven Contract (CDC) — podejście, w którym to konsumenci mikroserwisu definiują oczekiwania wobec API, a producent (czyli mikroserwis) weryfikuje zgodność przy każdej zmianie. Narzędzia takie jak Pact pozwalają testować te kontrakty automatycznie w CI/CD.
💡 „Gdybyśmy mieli kontrakty konsumenckie wcześniej — uniknęlibyśmy błędów na produkcji i nieporozumień z zespołem mobilnym” – przyznał później Darek.
Monitoring, tracing i chaos w logach
Z czasem pojawiło się więcej mikroserwisów. I więcej pytań:
-
Gdzie utknęło żądanie?
-
Dlaczego płatność trwała 4 sekundy?
-
Kto wysłał ten dziwny request?
Logi z jednego serwisu przestały wystarczać. Darek wdrożył centralny monitoring (ELK Stack), a potem distributed tracing (np. Jaeger). I zrozumiał, że bez identyfikatora correlation-id w nagłówkach niczego nie da się poskładać.
DevOps
W miarę jak pojawiało się więcej mikroserwisów, więcej pipeline’ów CI/CD, więcej testów, Darek zrozumiał, że same zmiany w kodzie to za mało.
🔹 Musiał przygotować procesy wdrożeniowe z podziałem na środowiska.
🔹 Zautomatyzować testy integracyjne i rollback w przypadku błędów.
🔹 Wdrożyć monitoring stanu zdrowia usług (healthcheck, readiness, liveness).
🔹 I wreszcie — spiąć to wszystko z GitLab CI i ArgoCD.
„Mikroserwisy bez kultury DevOps to jak wyścigówka bez kierowcy – teoretycznie szybka, ale łatwo o kraksę.”
Skalowalność i autoscaling
Ruch wzrósł. Płatności musiały działać szybko, więc dorzucono autoscaling w Kubernetesie. Ale... przy skoku ruchu nowe instancje nie miały cache’a i ładowały dane z opóźnieniem.
Nauczył się, że skalowalność pozioma nie rozwiązuje wszystkiego, jeśli nie pomyślisz o stanie aplikacji, cache’ach i bazach danych.
Podsumowanie: Mikroserwisy? To nie tylko podział na pliki
Darek zaczął od pomysłu: "podzielmy system, będzie lepiej".
Ale każdy krok — DNS, retry, service discovery, tracing, versioning, deployment, skalowanie — wymagał świadomości, planowania i odpowiedzialności.
💡 Mikroserwisy to nie tylko “dzielenie systemu na kawałki”. To świadome projektowanie rozproszonego ekosystemu z wszystkimi jego pułapkami i możliwościami.
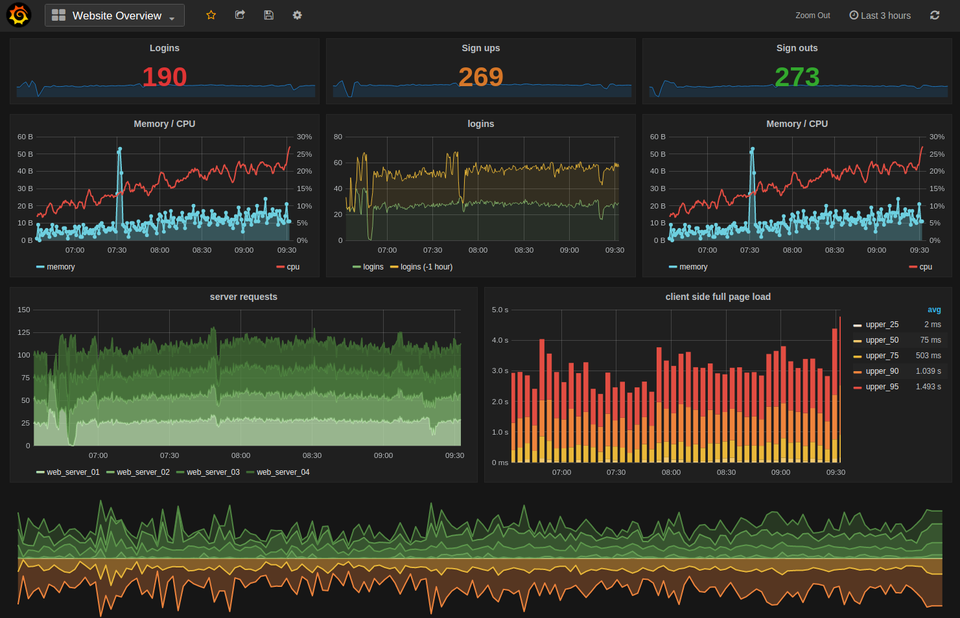
„Dziś, gdy ktoś mówi mi, że ‘chce sobie coś wydzielić’, pytam: ‘czy jesteś gotów na konsekwencje?’” – śmieje się Darek, patrząc na swój dashboard Prometheusa.
Część praktyk i wzorców zdążyłeś już poznać w moich poprzednich wpisach. Kolejne będą się pojawiać w następnych. Więc zapraszam do czytania i śledzenia mojego bloga!
%20series.%20The%20image%20shows%20multiple%20layers%20of%20security%20concepts,%20inc.webp)



%20series.%20The%20image%20shows%20multiple%20layers%20of%20security%20concepts,%20inc.webp)
